
Google recently introduced a revolutionary AI video generator large language model (LLM) for video generation called VideoPoet. This model is designed to perform various tasks, including text-to-video, image-to-video, video stylization, video inpainting and outpainting, and video-to-audio conversion.
What is VideoPoet?
VideoPoet is a simple modeling method that can convert any autoregressive language model or large language model (LLM) into a high-quality video generator. It demonstrates state-of-the-art video generation, particularly in producing a wide range of large, interesting, and high-fidelity motions.
What sets VideoPoet apart is its unique architecture, which transforms traditional language models into sophisticated video generators. With its powerful MAGVIT-2 encoder at its core, it can transform simple prompts into visually captivating and dynamic videos. The model adopts a decoder-only transformer architecture, showcasing its zero-shot capabilities and allowing it to create content it has not been explicitly trained on.
Capabilities of VideoPoet
VideoPoet can output high-motion variable-length videos given a text prompt. It can also output audio to match an input video without using text as guidance. This makes VideoPoet highly versatile and capable of multitasking on a variety of video-centric inputs and outputs.
The key strength of VideoPoet is its ability to learn across different modalities, bridging the gap between text, images, videos, and audio for a holistic understanding. This cross-modality learning capability enables the model to perform various video generation tasks, such as text-to-video, image-to-video, video stylization, video inpainting and outpainting, and video-to-audio generation.
How Does it Work?
VideoPoet trains an autoregressive language model to learn across video, image, audio, and text modalities through the use of multiple tokenizers. Once the model generates tokens based on some context, the tokenizer decoders can convert them back into a viewable representation.
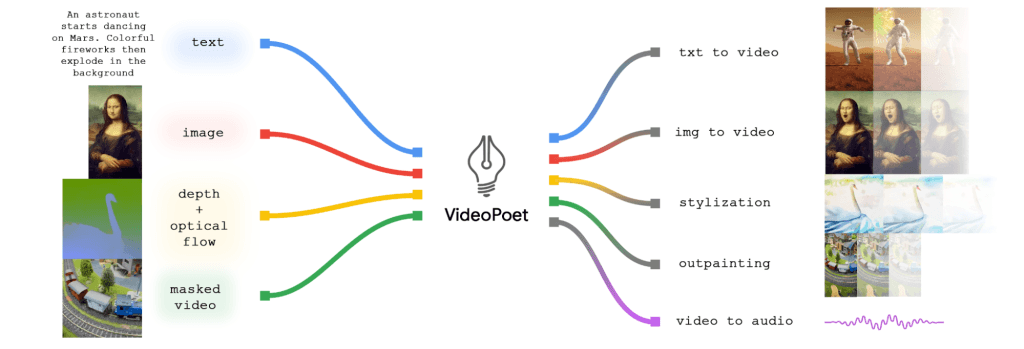
This model follows a two-step training process similar to other LLMs: pretraining and task-specific adaptation. The pre-trained LLM provides the foundation, allowing adaptation for several video generation tasks, making it a highly adaptable and efficient tool.
Another remarkable feature of VideoPoet is its interactive editing capabilities. Users can benefit from extended input videos, controllable motions, and stylized effects guided by text prompts, empowering them to create personalized and engaging content.
In summary, Google VideoPoet AI video generator is a powerful and versatile multimodal LLM that can generate high-motion variable-length videos, learn across different modalities, and offer interactive editing capabilities.